

DP-200 Practice Test Free – 50 Questions to Test Your Knowledge
Are you preparing for the DP-200 certification exam? If so, taking a DP-200 practice test free is one of the best ways to assess your knowledge and improve your chances of passing. In this post, we provide 50 free DP-200 practice questions designed to help you test your skills and identify areas for improvement.
By taking a free DP-200 practice test, you can:
- Familiarize yourself with the exam format and question types
- Identify your strengths and weaknesses
- Gain confidence before the actual exam
50 Free DP-200 Practice Questions
Below, you will find 50 free DP-200 practice questions to help you prepare for the exam. These questions are designed to reflect the real exam structure and difficulty level.
DRAG DROP - You need to provision the polling data storage account. How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:


Which two metrics should you use to identify the appropriate RU/s for the telemetry data? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Number of requests
B. Number of requests exceeded capacity
C. End to end observed read latency at the 99 th percentile
D. Session consistency
E. Data + Index storage consumed
F. Avg Throughput/s
HOTSPOT - You need to ensure that Azure Data Factory pipelines can be deployed. How should you configure authentication and authorization for deployments? To answer, select the appropriate options in the answer choices. NOTE: Each correct selection is worth one point. Hot Area:


You need to set up Azure Data Factory pipelines to meet data movement requirements. Which integration runtime should you use?
A. self-hosted integration runtime
B. Azure-SSIS Integration Runtime
C. .NET Common Language Runtime (CLR)
D. Azure integration runtime

You need to implement event processing by using Stream Analytics to produce consistent JSON documents. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Define an output to Cosmos DB.
B. Define a query that contains a JavaScript user-defined aggregates (UDA) function.
C. Define a reference input.
D. Define a transformation query.
E. Define an output to Azure Data Lake Storage Gen2.
F. Define a stream input.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You need to configure data encryption for external applications. Solution: 1. Access the Always Encrypted Wizard in SQL Server Management Studio 2. Select the column to be encrypted 3. Set the encryption type to Deterministic 4. Configure the master key to use the Azure Key Vault 5. Validate configuration results and deploy the solution Does the solution meet the goal?
A. Yes
B. No
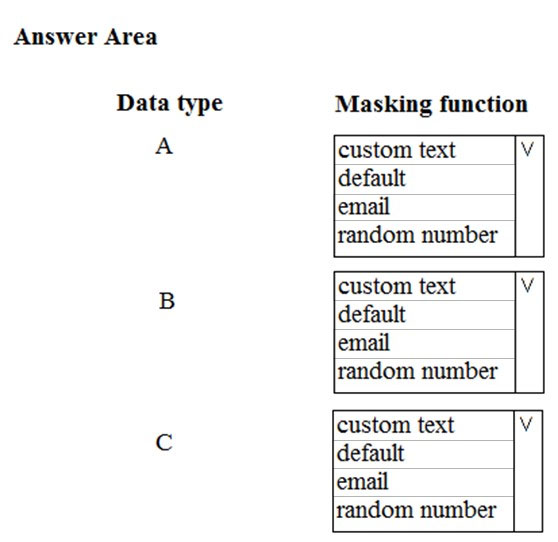
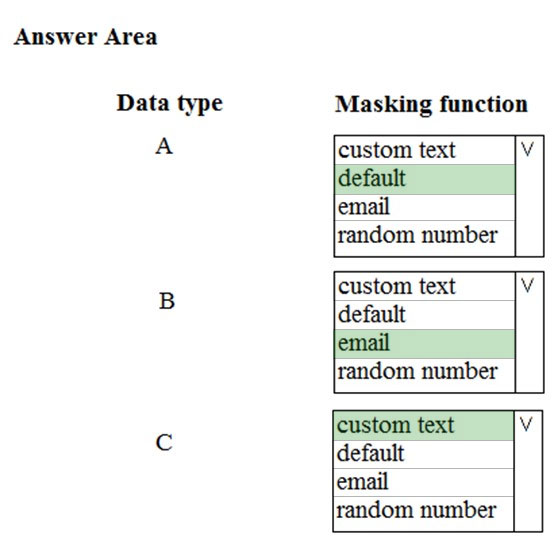
HOTSPOT - You need to mask tier 1 data. Which functions should you use? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You need to configure data encryption for external applications. Solution: 1. Access the Always Encrypted Wizard in SQL Server Management Studio 2. Select the column to be encrypted 3. Set the encryption type to Deterministic 4. Configure the master key to use the Windows Certificate Store 5. Validate configuration results and deploy the solution Does the solution meet the goal?
A. Yes
B. No
HOTSPOT - You have an Azure data factory that has two pipelines named PipelineA and PipelineB. PipelineA has four activities as shown in the following exhibit.PipelineB has two activities as shown in the following exhibit.
You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings: ✑ Operator: Greater than ✑ Aggregation type: Total ✑ Threshold value: 2 ✑ Aggregation granularity (Period): 5 minutes ✑ Frequency of evaluation: Every 5 minutes Data Factory monitoring records the failures shown in the following table.
For each of the following statements, select yes if the statement is true. Otherwise, select no. NOTE: Each correct answer selection is worth one point. Hot Area:


After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You need setup monitoring for tiers 6 through 8. What should you configure?
A. extended events for average storage percentage that emails data engineers
B. an alert rule to monitor CPU percentage in databases that emails data engineers
C. an alert rule to monitor CPU percentage in elastic pools that emails data engineers
D. an alert rule to monitor storage percentage in databases that emails data engineers
E. an alert rule to monitor storage percentage in elastic pools that emails data engineers
You have an Azure data solution that contains an enterprise data warehouse in Azure Synapse Analytics named DW1. Several users execute adhoc queries to DW1 concurrently. You regularly perform automated data loads to DW1. You need to ensure that the automated data loads have enough memory available to complete quickly and successfully when the adhoc queries run. What should you do?
A. Hash distribute the large fact tables in DW1 before performing the automated data loads.
B. Assign a larger resource class to the automated data load queries.
C. Create sampled statistics for every column in each table of DW1.
D. Assign a smaller resource class to the automated data load queries.
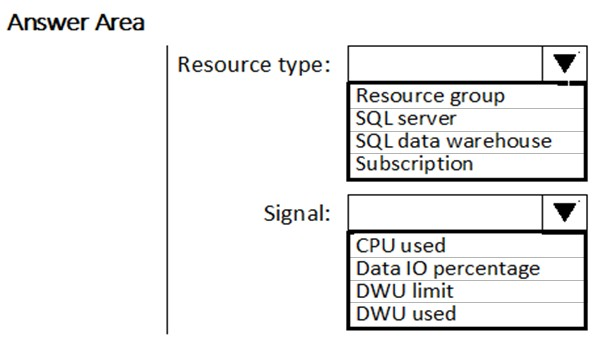
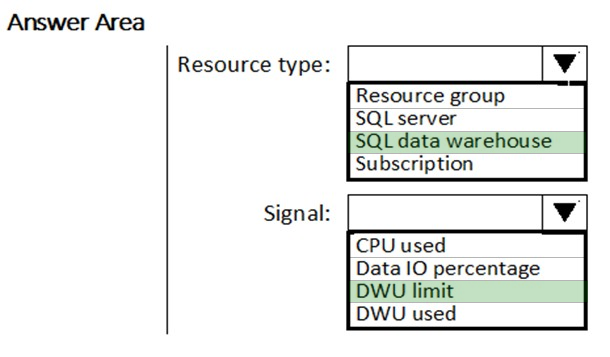
HOTSPOT - You need to receive an alert when Azure Synapse Analytics consumes the maximum allotted resources. Which resource type and signal should you use to create the alert in Azure Monitor? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
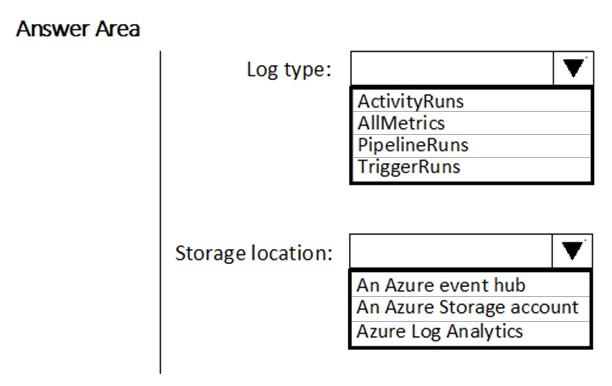
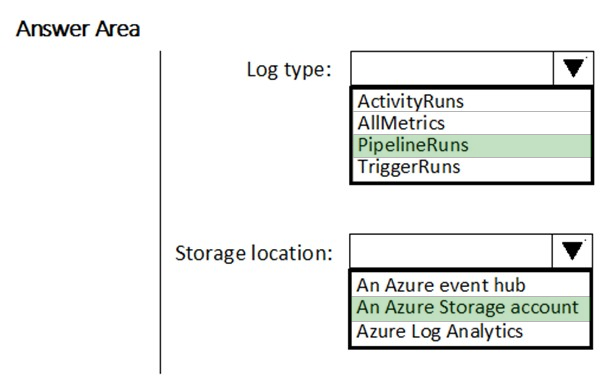
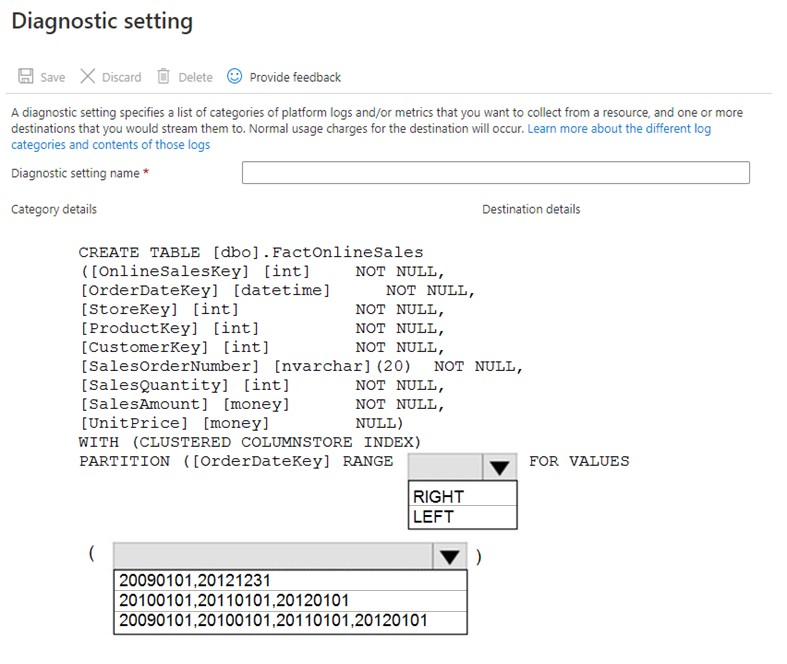
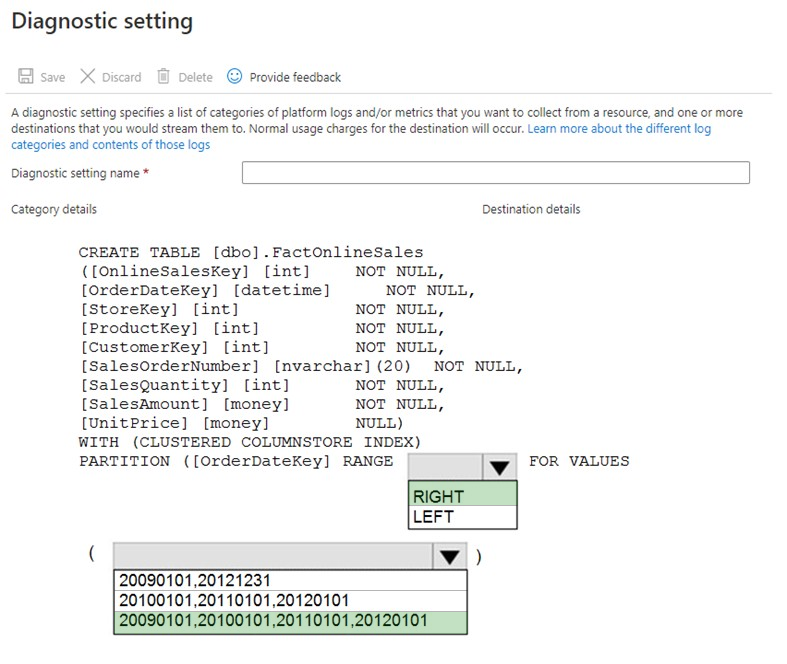
HOTSPOT - You have a new Azure Data Factory environment. You need to periodically analyze pipeline executions from the last 60 days to identify trends in execution durations. The solution must use Azure Log Analytics to query the data and create charts. Which diagnostic settings should you configure in Data Factory? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
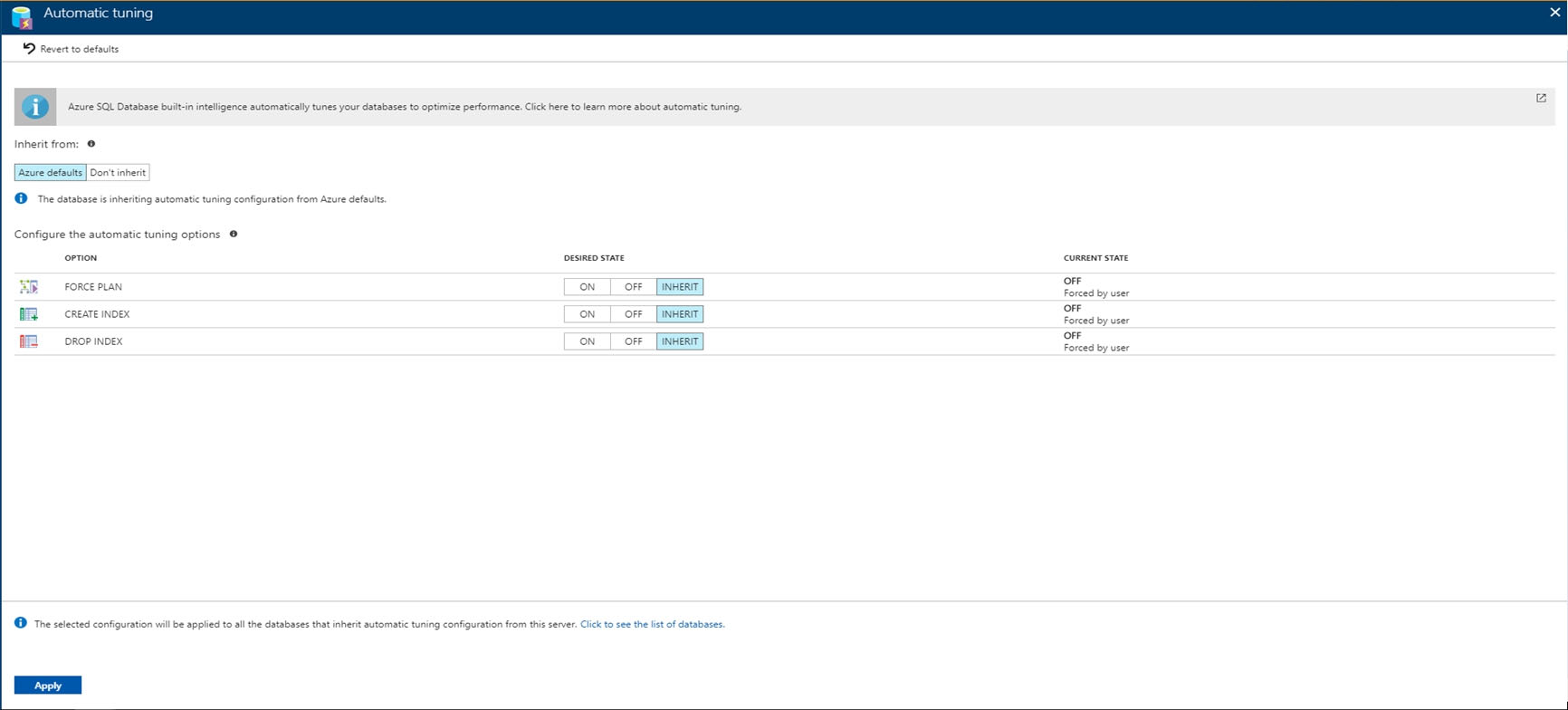
HOTSPOT - You are implementing automatic tuning mode for Azure SQL databases. Automatic tuning mode is configured as shown in the following table.For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:


You have an Azure Stream Analytics job. You need to ensure that the job has enough streaming units provisioned. You configure monitoring of the SU% Utilization metric. Which two additional metrics should you monitor? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Watermark Delay
B. Late Input Events
C. Out of order Events
D. Backlogged Input Events
E. Function Events
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.The partition key is set to the OrderId attribute. Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete. You need to reduce the amount of time it takes to execute the problematic queries. Solution: You increase the Request Units (RUs) for the database. Does this meet the goal?
A. Yes
B. No
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior. You need to implement logging. Solution: Use information stored in Azure Active Directory reports. Does the solution meet the goal?
A. Yes
B. No
You are monitoring an Azure Stream Analytics job. You discover that the Backlogged Input Events metric is increasing slowly and is consistently non-zero. You need to ensure that the job can handle all the events. What should you do?
A. Change the compatibility level of the Stream Analytics job.
B. Increase the number of streaming units (SUs).
C. Create an additional output stream for the existing input stream.
D. Remove any named consumer groups from the connection and use $default.
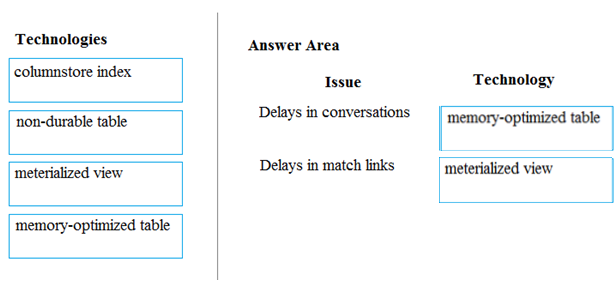
DRAG DROP - A company builds an application to allow developers to share and compare code. The conversations, code snippets, and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application allows for searches of historical conversations and code snippets. When users share code snippets, the code snippet is compared against previously share code snippets by using a combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to the match is added to the conversation. Customers report the following issues: ✑ Delays occur during live conversations ✑ A delay occurs before matching links appear after code snippets are added to conversations You need to resolve the performance issues. Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
You manage a process that performs analysis of daily web traffic logs on an HDInsight cluster. Each of the 250 web servers generates approximately 10 megabytes (MB) of log data each day. All log data is stored in a single folder in Microsoft Azure Data Lake Storage Gen 2. You need to improve the performance of the process. Which two changes should you make? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Combine the daily log files for all servers into one file
B. Increase the value of the mapreduce.map.memory parameter
C. Move the log files into folders so that each day’s logs are in their own folder
D. Increase the number of worker nodes
E. Increase the value of the hive.tez.container.size parameter
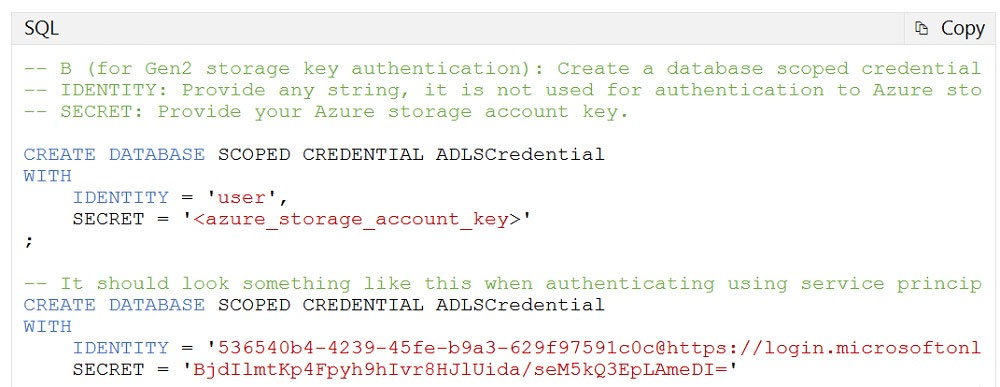
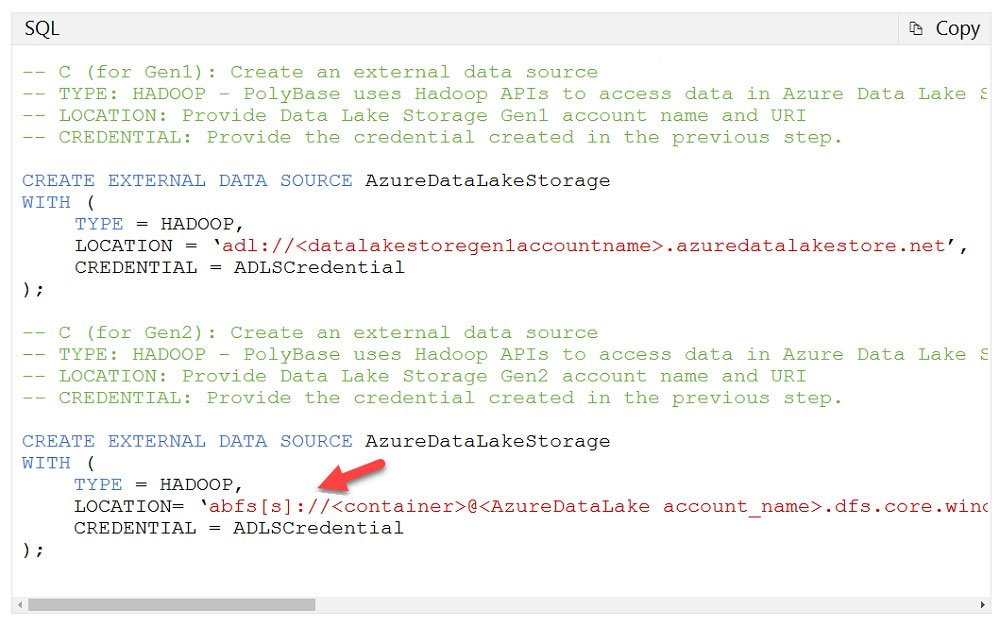
You have an Azure Data Lake Storage Gen2 account. You have a number of CSV files loaded in the account. Each file has a header row. After the header row is a property that is formatted by carriage return (/r) and line feed (/n). You need to load the files daily as a batch into Azure SQL Data warehouse using Polybase. You have to skip the header row when the files are imported. Which of the following actions would you take to implement this requirement? (Choose three.)
A. Create an external data source and ensure to use the abfs location
B. Create an external data source and ensure to use the Hadoop location
C. Create an external file format and set the First_row option
D. Create a database scoped credential that uses OAuth2 token and a key
E. Use the CREATE EXTERNAL TABLE AS SELECT and create a view that removes the empty row
A company has an Azure SQL Datawarehouse. They have a table named whizlab_salesfact that contains data for the past 12 months. The data is partitioned by month. The table contains around a billion rows. The table has clustered columnstore indexes. At the beginning of each month you need to remove the data from the table that is older than 12 months. Which of the following actions would you implement for this requirement? (Choose three.)
A. Create a new empty table named XYZ_salesfact_new that has the same schema as XYZ_salesfact
B. Drop the XYZ_salesfact_new table
C. Copy the data to the new table by using CREATE TABLE AS SELECT (CTAS)
D. Truncate the partition containing the stale data
E. Switch the partition containing the stale data from XYZ_salesfact to XYZ_salesfact_new
F. Execute the DELETE statement where the value in the Date column is greater than 12 months
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to create large data sets on db2. You need to ensure that missing indexes are created automatically by Azure in db2. The solution must apply ONLY to db2. To complete this task, sign in to the Azure portal.
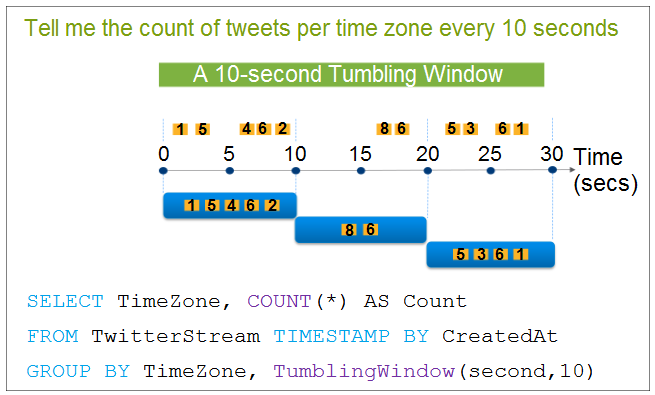
You have to implement Azure Stream Analytics Functions as part of your data streaming solution. The solution has the following requirements: - Segment the data stream into distinct time segments that do not repeat or overlap - Segment the data stream into distinct time segments that repeat and can overlap - Segment the data stream to produce an output when an event occurs Which of the following windowing function would you use for the following requirement? `Segment the data stream into distinct time segments that do not repeat or overlap`
A. Hopping
B. Session
C. Sliding
D. Tumbling
You have an Azure Cosmos DB database that uses the SQL API. You need to delete stale data from the database automatically. What should you use?
A. soft delete
B. Low Latency Analytical Processing (LLAP)
C. schema on read
D. Time to Live (TTL)
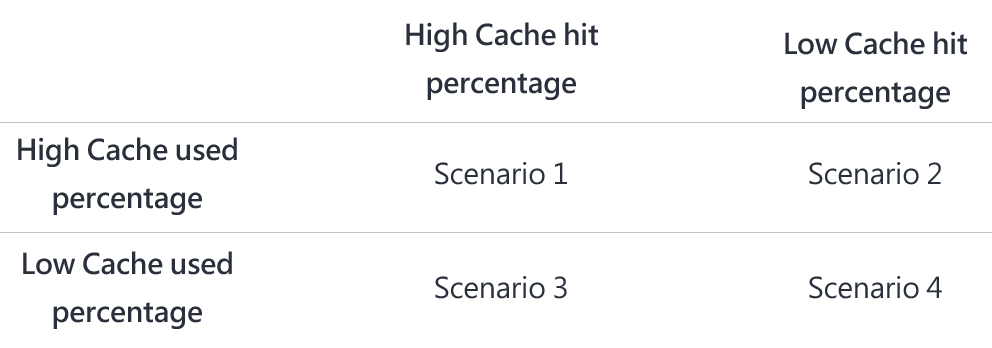
Overview - XYZ is an online training provider. Current Environment - The company currently has Microsoft SQL databases that are split into different categories or tiers. Some of the databases are used by Internal users, some by external partners and external distributions. Below is the List of applications, tiers and their individual requirements:Below are the current requirements of the company: * For Tier 4 and Tier 5 databases, the backup strategy must include the following: - Transactional log backup every hour - Differential backup every day - Full backup every week * Backup strategies must be in place for all standalone Azure SQL databases using methods available with Azure SQL databases * Tier 1 database must implement the following data masking logic: - For Data type XYZ-A `" Mask 4 or less string data type characters - For Data type XYZ-B `" Expose the first letter and mask the domain - For Data type XYZ-C `" Mask everything except characters at the beginning and the end * All certificates and keys are internally managed in on-premise data stores * For Tier 2 databases, if there are any conflicts between the data transfer from on-premise, preference should be given to on-premise data. * Monitoring must be setup on every database * Applications with Tiers 6 through 8 must ensure that unexpected resource storage usage is immediately reported to IT data engineers. * Azure SQL Data warehouse would be used to gather data from multiple internal and external databases. * The Azure SQL Data warehouse must be optimized to use data from its cache * The below metrics must be available when it comes to the cache: - Metric XYZ-A `" Low cache hit %, high cache usage % - Metric XYZ-B `" Low cache hit %, low cache usage % - Metric XYZ-C `" high cache hit %, high cache usage % * The reporting data for external partners must be stored in Azure storage. The data should be made available during regular business hours in connecting regions. * The reporting for Tier 9 needs to be moved to Event Hubs. * The reporting for Tier 10 needs to be moved to Azure Blobs. The following issues have been identified in the setup: * The External partners have control over the data formats, types and schemas * For External based clients, the queries can't be changed or optimized * The database development staff are familiar with T-SQL language * Because of the size and amount of data, some applications and reporting features are not performing at SLA levels. You have to implement logging for monitoring the data warehousing solution. Which of the following would you log?
A. Requeststeps
B. DmWorkers
C. SQLRequest
D. ExecRequest
HOTSPOT - You have an Azure Cosmos DB database. You need to use Azure Stream Analytics to check for uneven distributions of queries that can affect performance. Which two settings should you configure? To answer, select the appropriate settings in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
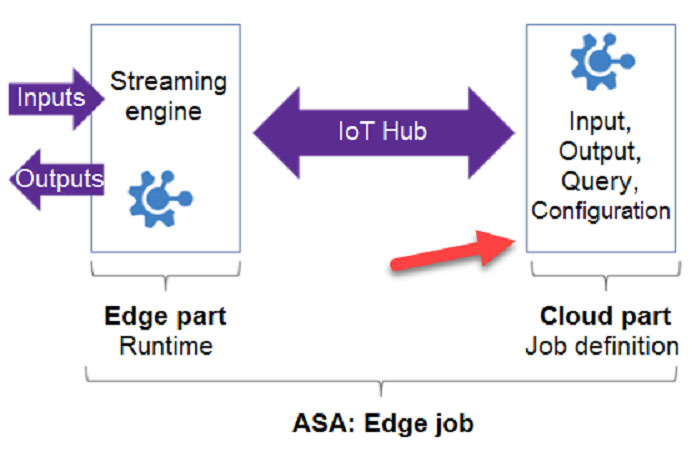
You need to deploy a Microsoft Azure Stream Analytics job for an IoT based solution. The solution must minimize latency. The solution must also minimize the bandwidth usage between the job and the IoT device. Which of the following actions must you perform for this requirement? (Choose four.)
A. Ensure to configure routes
B. Create an Azure Blob storage container
C. Configure Streaming Units
D. Create an IoT Hub and add the Azure Stream Analytics modules to the IoT Hub namespace
E. Create an Azure Stream Analytics edge job and configure job definition save location
F. Create an Azure Stream Analytics cloud job and configure job definition save location

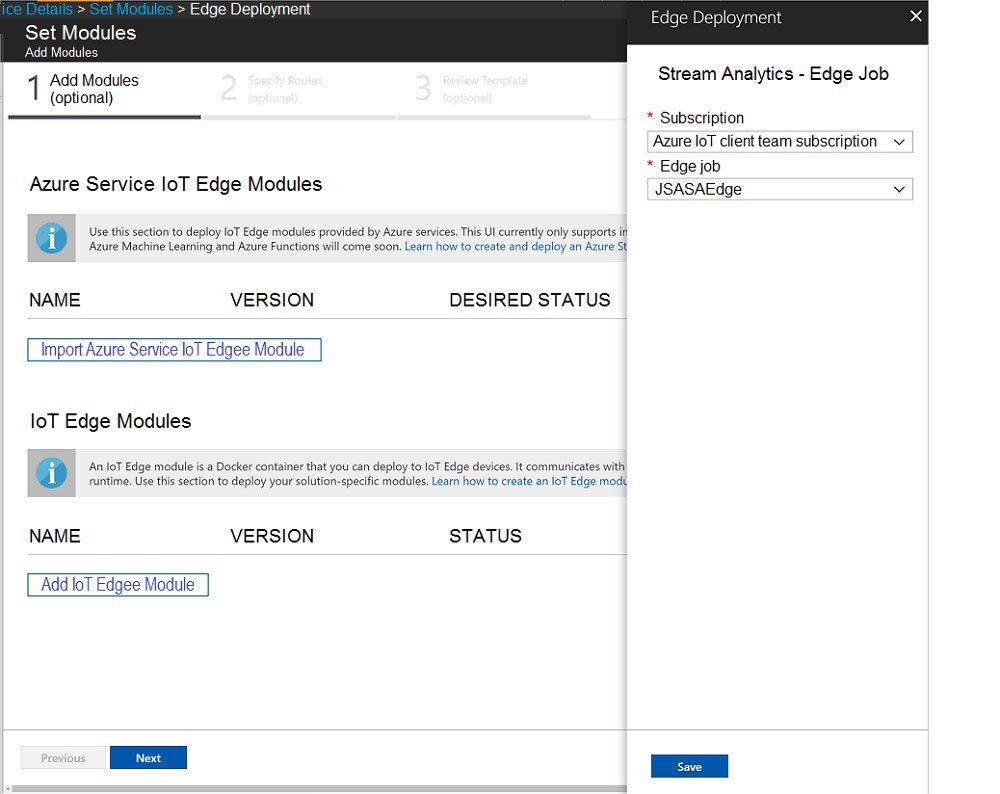
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following three workloads: ✑ A workload for data engineers who will use Python and SQL ✑ A workload for jobs that will run notebooks that use Python, Scala, and SQL ✑ A workload that data scientists will use to perform ad hoc analysis in Scala and R The enterprise architecture team at your company identifies the following standards for Databricks environments: ✑ The data engineers must share a cluster. ✑ The job cluster will be managed by using a request process whereby data scientists and data engineers provide packaged notebooks for deployment to the cluster. ✑ All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity. Currently, there are three data scientists. You need to create the Databricks clusters for the workloads. Solution: You create a High Concurrency cluster for each data scientist, a High Concurrency cluster for the data engineers, and a Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure storage account 2. Create a workload group using the Azure storage account name as the pool name 3. Load the data using the INSERT`¦SELECT statement Does the solution meet the goal?
A. Yes
B. No
You have an Azure SQL database that contains a table named Customer. Customer contains the columns shown in the following table.You apply a masking rule as shown in the following table.
Which users can view the email addresses of the customers?
A. Server administrators and all users who are granted the UNMASK permission to the Customer_Email column only.
B. All users who are granted the UNMASK permission to the Customer_Email column only.
C. Server administrators only.
D. Server administrators and all users who are granted the SELECT permission to the Customer_Email column only.
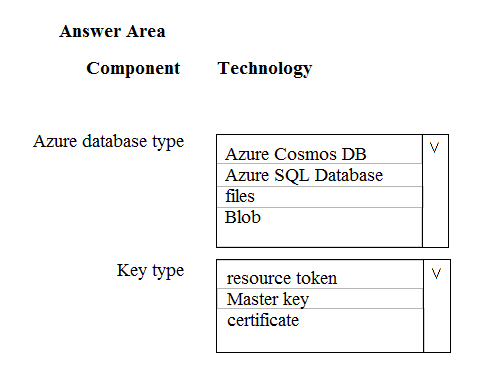
HOTSPOT - You develop data engineering solutions for a company. An application creates a database on Microsoft Azure. You have the following code:Which database and authorization types are used? To answer, select the appropriate option in the answer area. NOTE: Each correct selection is worth one point. Hot Area:


HOTSPOT - You have an Azure subscription that contains the following resources: ✑ An Azure Active Directory (Azure AD) tenant that contains a security group named Group1 ✑ An Azure Synapse Analytics SQL pool named Pool1 You need to control the access of Group1 to specific columns and rows in a table in Pool1. Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area. Hot Area:


You have an Azure Blob storage account. Developers report that an HTTP 403 (Forbidden) error is generated when a client application attempts to access the storage account. You cannot see the error messages in Azure Monitor. What is a possible cause of the error?
A. The client application is using an expired shared access signature (SAS) when it sends a storage request.
B. The client application deleted, and then immediately recreated a blob container that has the same name.
C. The client application attempted to use a shared access signature (SAS) that did not have the necessary permissions.
D. The client application attempted to use a blob that does not exist in the storage service.
You have an Azure subscription the contains the resources shown in the following table:All the resources have the default encryption settings. You need to ensure that all the data stored in the resources is encrypted at rest. What should you do?
A. Enable Azure Storage encryption for storageaccount1.
B. Enable Transparent Data Encryption (TDE) for synapsedb1.
C. Enable Azure Storage encryption for storageaccount2.
D. Enable encryption at rest for cosmosdb1.
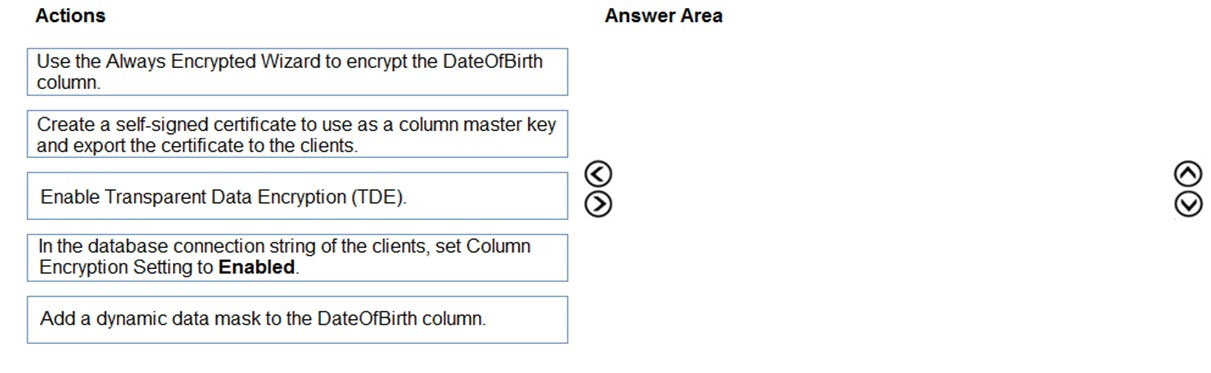
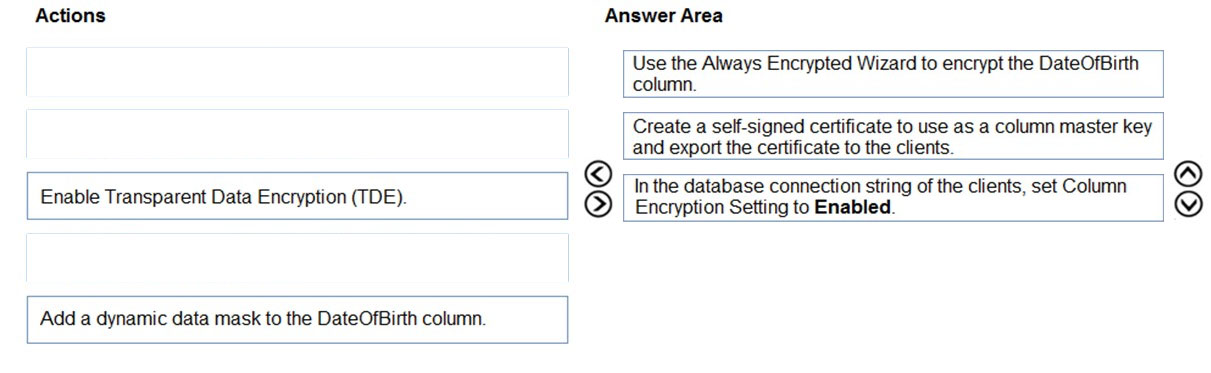
DRAG DROP - You have an ASP.NET web app that uses an Azure SQL database. The database contains a table named Employee. The table contains sensitive employee information, including a column named DateOfBirth. You need to ensure that the data in the DateOfBirth column is encrypted both in the database and when transmitted between a client and Azure. Only authorized clients must be able to view the data in the column. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions in the answer area and arrange them in the correct order. Select and Place:
You have a data warehouse in Azure Synapse Analytics. You need to ensure that the data in the data warehouse is encrypted at rest. What should you enable?
A. Transparent Data Encryption (TDE)
B. Secure transfer required
C. Always Encrypted for all columns
D. Advanced Data Security for this database
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create a remote service binding pointing to the Azure Data Lake Gen 2 storage account 2. Create an external file format and external table using the external data source 3. Load the data using the CREATE TABLE AS SELECT statement Does the solution meet the goal?
A. Yes
B. No
You have an Azure SQL server named Server1 that hosts two development databases named DB1 and DB2. You have an administrative workstation that has an IP address of 192.168.8.8. The development team at your company has an IP addresses in the range of 192.168.8.1 to 192.168.8.5. You need to set up firewall rules to meet the following requirements: ✑ Allows connection from your workstation to both databases. ✑ The development team must be able connect to DB1 but must be prevented from connecting to DB2. ✑ Web services running in Azure must be able to connect to DB1 but must be prevented from connecting to DB2. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Create a firewall rule on DB1 that has a start IP address of 192.168.8.1 and an end IP address of 192.168.8.5.
B. Create a firewall rule on DB1 that has a start and end IP address of 0.0.0.0.
C. Create a firewall rule on Server1 that has a start IP address of 192.168.8.1 and an end IP address of 192.168.8.5.
D. Create a firewall rule on DB1 that has a start and end IP address of 192.168.8.8.
E. Create a firewall rule on Server1 that has a start and end IP address of 192.168.8.8.
Note: This question is a part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals. You develop a data ingestion process that will import data to an enterprise data warehouse in Azure Synapse Analytics. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to load the data from the Azure Data Lake Gen 2 storage account into the Data Warehouse. Solution: 1. Create an external data source pointing to the Azure Data Lake Gen 2 storage account 2. Create an external file format and external table using the external data source 3. Load the data using the CREATE TABLE AS SELECT statement Does the solution meet the goal?
A. Yes
B. No
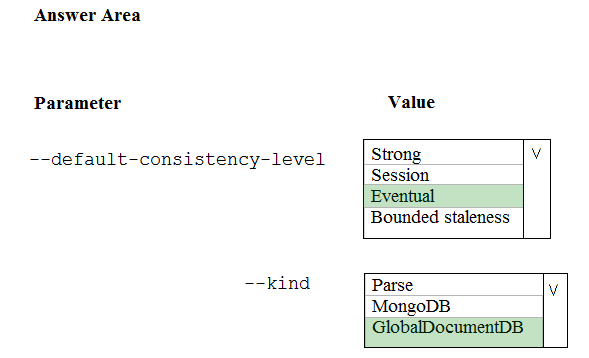
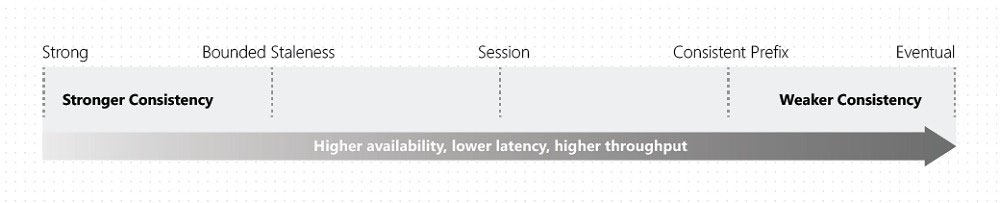
HOTSPOT - A company is planning to use Microsoft Azure Cosmos DB as the data store for an application. You have the following Azure CLI command: az cosmosdb create -`"name "cosmosdbdev1" `"-resource-group "rgdev" You need to minimize latency and expose the SQL API. How should you complete the command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:

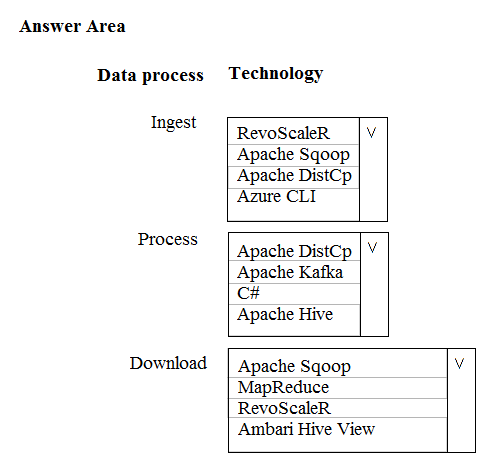
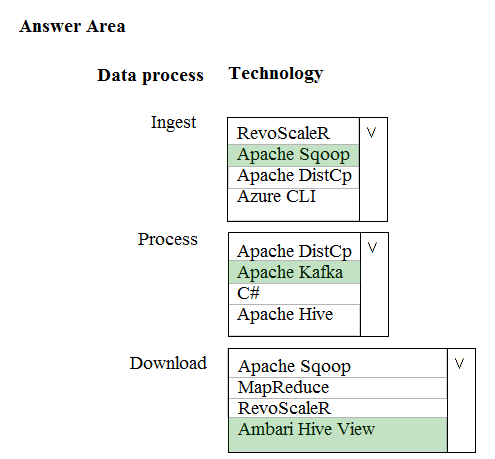
HOTSPOT - A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements: ✑ Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service ✑ Use an Azure Data Lake Storage account to store processed data ✑ Allow users to download processed data You need to recommend technologies for the solution. Which technologies should you use? To answer, select the appropriate options in the answer area. Hot Area:
You manage a solution that uses Azure HDInsight clusters. You need to implement a solution to monitor cluster performance and status. Which technology should you use?
A. Azure HDInsight .NET SDK
B. Azure HDInsight REST API
C. Ambari REST API
D. Azure Log Analytics
E. Ambari Web UI
Each day, company plans to store hundreds of files in Azure Blob Storage and Azure Data Lake Storage. The company uses the parquet format. You must develop a pipeline that meets the following requirements: ✑ Process data every six hours ✑ Offer interactive data analysis capabilities ✑ Offer the ability to process data using solid-state drive (SSD) caching ✑ Use Directed Acyclic Graph(DAG) processing mechanisms ✑ Provide support for REST API calls to monitor processes ✑ Provide native support for Python ✑ Integrate with Microsoft Power BI You need to select the appropriate data technology to implement the pipeline. Which data technology should you implement?
A. Azure SQL Data Warehouse
B. HDInsight Apache Storm cluster
C. Azure Stream Analytics
D. HDInsight Apache Hadoop cluster using MapReduce
E. HDInsight Spark cluster
Your company uses Azure Stream Analytics to monitor devices. The company plans to double the number of devices that are monitored. You need to monitor a Stream Analytics job to ensure that there are enough processing resources to handle the additional load. Which metric should you monitor?
A. Input Deserialization Errors
B. Early Input Events
C. Late Input Events
D. Watermark delay
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to create multiple pipelines in a new Azure Data Factory V2. You need to create the data factory, and then create a scheduled trigger for the planned pipelines. The trigger must execute every two hours starting at 24:00:00. To complete this task, sign in to the Azure portal.
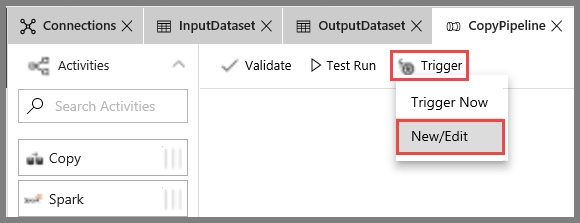
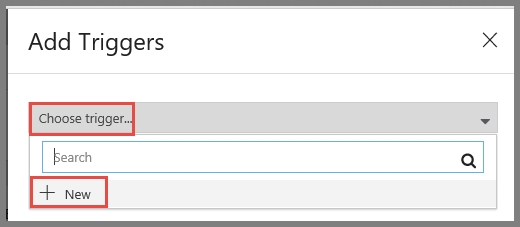
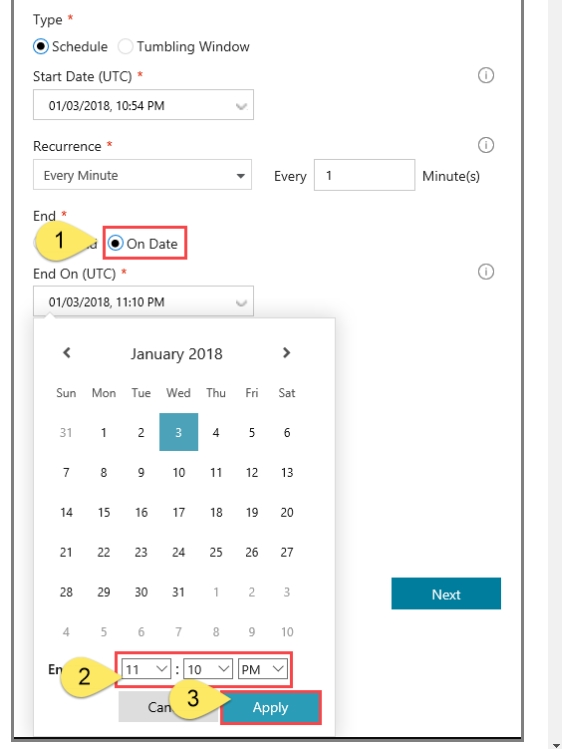
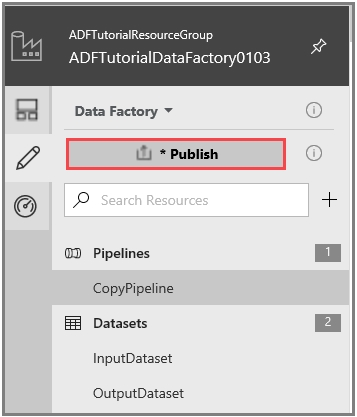
SIMULATION -Use the following login credentials as needed: Azure Username: xxxxx - Azure Password: xxxxx - The following information is for technical support purposes only: Lab Instance: 10277521 - You plan to generate large amounts of real-time data that will be copied to Azure Blob storage. You plan to create reports that will read the data from an Azure Cosmos DB database. You need to create an Azure Stream Analytics job that will input the data from a blob storage named storage10277521 to the Cosmos DB database. To complete this task, sign in to the Azure portal.
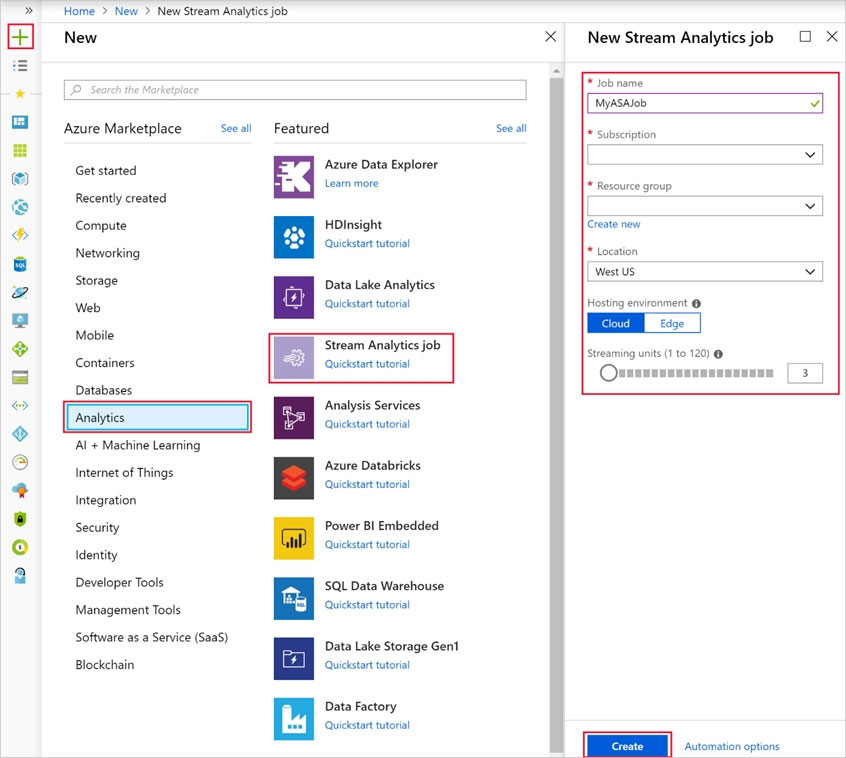
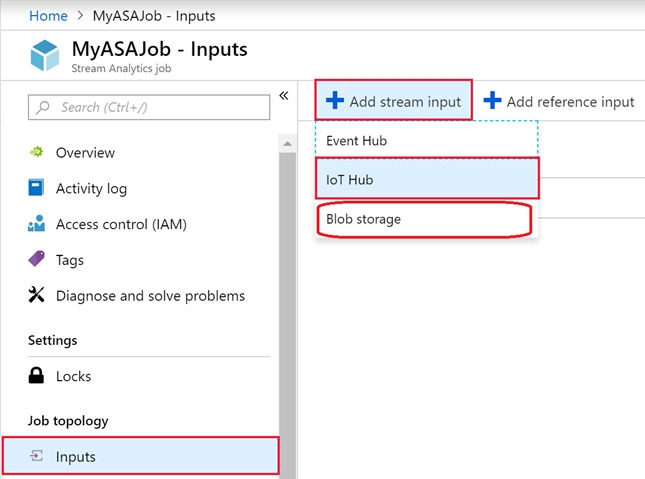
You have an Azure Stream Analytics query. The query returns a result set that contains 10,000 distinct values for a column named clusterID. You monitor the Stream Analytics job and discover high latency. You need to reduce the latency. Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Add a pass-through query.
B. Add a temporal analytic function.
C. Scale out the query by using PARTITION BY.
D. Convert the query to a reference query.
E. Increase the number of streaming units.
A company plans to use Azure SQL Database to support a mission-critical application. The application must be highly available without performance degradation during maintenance windows. You need to implement the solution. Which three technologies should you implement? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Premium service tier
B. Virtual machine Scale Sets
C. Basic service tier
D. SQL Data Sync
E. Always On availability groups
F. Zone-redundant configuration
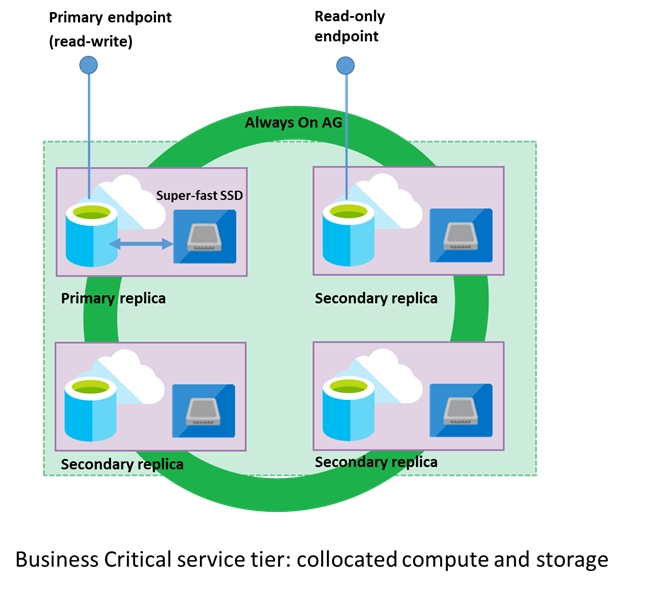
DRAG DROP - Your company plans to create an event processing engine to handle streaming data from Twitter. The data engineering team uses Azure Event Hubs to ingest the streaming data. You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs. Which three actions should you recommend be performed in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:


Get More DP-200 Practice Questions
If you’re looking for more DP-200 practice test free questions, click here to access the full DP-200 practice test.
We regularly update this page with new practice questions, so be sure to check back frequently.
Good luck with your DP-200 certification journey!